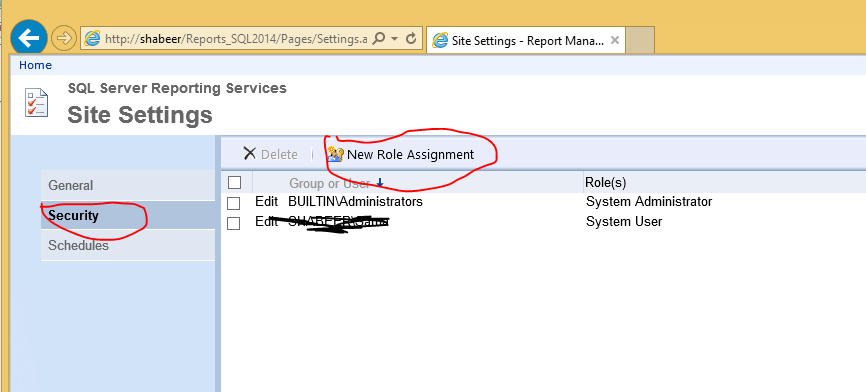
TOP Keyword is commonly used to get the Top Rows from a Result. SQL Server has option use it 'WITH TIES' to get similar rows together
WITH TIES
Used when you want to return two or more rows that tie for last place in the limited results set. Must be used with the ORDER BY clause. WITH TIES may cause more rows to be returned than the value specified in expression. For example, if expression is set to 5 but 2 additional rows match the values of the ORDER BY columns in row 5, the result set will contain 7 rows.
SELECT TOP (5) productid, unitprice FROM Production.Products
WHERE categoryid = 1 ORDER BY unitprice DESC;
You get the following result set.
productid unitprice
----------- ---------------------
38 263.50
43 46.00
2 19.00
1 18.00
35 18.00
If you want provide solutions to turn this query into a deterministic one—one solution that includes ties and another that breaks the ties. First, address the version that includes all ties by using the WITH TIES option. Add this option to the query, as follows.
SELECT TOP (5) WITH TIES productid, unitprice FROM Production.Products
WHERE categoryid = 1 ORDER BY unitprice DESC;
You get the following output, which includes ties.
productid unitprice
----------- ---------------------
38 263.50
43 46.00
2 19.00
1 18.00
35 18.00
76 18.00
WITH TIES
Used when you want to return two or more rows that tie for last place in the limited results set. Must be used with the ORDER BY clause. WITH TIES may cause more rows to be returned than the value specified in expression. For example, if expression is set to 5 but 2 additional rows match the values of the ORDER BY columns in row 5, the result set will contain 7 rows.
SELECT TOP (5) productid, unitprice FROM Production.Products
WHERE categoryid = 1 ORDER BY unitprice DESC;
You get the following result set.
productid unitprice
----------- ---------------------
38 263.50
43 46.00
2 19.00
1 18.00
35 18.00
If you want provide solutions to turn this query into a deterministic one—one solution that includes ties and another that breaks the ties. First, address the version that includes all ties by using the WITH TIES option. Add this option to the query, as follows.
SELECT TOP (5) WITH TIES productid, unitprice FROM Production.Products
WHERE categoryid = 1 ORDER BY unitprice DESC;
You get the following output, which includes ties.
productid unitprice
----------- ---------------------
38 263.50
43 46.00
2 19.00
1 18.00
35 18.00
76 18.00